
Introduction to Machine Learning for a programmer
Posted by admin on March 15, 2017
This article is aimed at explaining the term "Machine Learning" (ML) to (conventional) programmers. Since, I have been on both sides, been a conventional programmer and am currently a Machine Learning enthusiast, so I think I am in a unique position to distinguish and explain the term to conventional programmers so they can relate and understand the key differences in the approach and results.
Conventional Programmers find it hard to understand the concept of machine learning as they confine their thinking to be terms of writing programs that can get the job done. The most common response I get when I try to explain the concepts of ML to them is that, "I can write a program that can do the exact same thing and as the conditions change I can tweak my program based on input conditions and it will start giving correct results for new set of rules". However, as we will see below, ML needs a paradigm shift in the thought process for a conventional programmer.
Points to note:
- In this attempt I am going to oversimplify some concepts of ML but I am going to not distort the truth and try to explain ML in as easy terms as possible.
- While reading this article please keep in mind that Machine learning is a very different way of looking at the problem from what we (programmers) are used to doing when solving a problem using conventional programming. Hence to understand the concept try (very hard) not to relate this to any conventional programming paradigm as that will only make it harder to understand the concept.
As is with any other programming tutorial it really works better (and probably easier) if we start with specific example (remember Hello World examples) since we love doing stuff than just reading things.
Let me take an example of how to identify if a string is a valid email address or not. I am taking this example since in conventional programming a very basic program needs to be written to identify this.
Let me first start by defining what I consider a valid email address. For this article oversimplifying the definition of a valid email as:
- A string of the format local-part@domain is a valid email
- Local-part may use any of these ASCII characters
- uppercase and lowercase Latin letters A to Z and a to z;
- digits 0 to 9;
- special characters not allowed !#$%&'*+-/=?^_`{|}~; (Though this is not the case)
- dot ., provided that it is not the first or last character
- Lets assume white space ' ' is not allowed
- Domain part
- it must match the requirements for a hostname (https://en.wikipedia.org/wiki/Hostname)
So as per our rules above, a few valid email addresses are:
[email protected]
[email protected]
[email protected]
user8@localhost
[email protected]
and invalid emails are:
abc.test2.codefire (no @)
ab [email protected] (space used)
[email protected] (double dot after @)
[email protected]
In conventional programming it is really easy to write a program that can confirm if the string is a valid email address or not. All we have to do is write a regular expression (regex) based on the rules to match the string with that pattern. In any high level language this is a really miniscule task.
In conventional programming it is really easy to write a program that can confirm if the string is a valid email address or not. All we have to do is write a regular expression (regex) based on the rules to match the string with that pattern. In any high level language this is a really miniscule task.
However, when we approach this same task with machine learning, we do not write a program to match a specific pattern (email pattern in this case), keyword here being 'specific'. A Machine Learning program is written to find patterns in the any given dataset and the program itself does not know anything about the type of pattern it needs to identify. Theoretically, a single ML program once written should be able to read different datasets and determine a pattern in that data. Also, the data that needs to be provided to a ML program may not be raw data, for example raw email addresses in our case. The data needs to be prepared in such a way that it highlights the rules that govern the distinction between what's correct result and what's not. Keep these in mind and lets go back to our email example.
So for solving the email problem with ML, we need to create dataset of valid / invalid emails based on the rules that we defined above. In ML terminology this dataset it called training data ( as our model gets trained with this dataset) and the rules that we use to identify email are called 'feature set' (meaning the distinguishing features that help us identify whether it's a valid email or not). So for our oversimplified email rules the feature set will be:
- Does the local part of the string only have ASCII characters?
- Does local part only allowed characters (have uppercase and lowercase Latin letters A to Z and a to z or have digits 0 to 9 or have dots)?
- Does local part of the email string have special characters?
- Does the local of the email string part have dot as first character or last character?
- Does the local part have space character?
- Does the email string have @ symbol?
- Does the domain part matches requirement for hostname (keeping it simple for hostname part and not writing too many rules)
Based on above examples that I gave for valid and invalid emails our dataset with the above defined 7 feature set will look like:
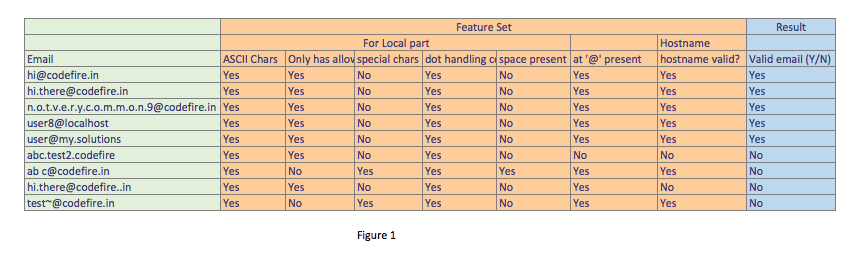
So looking at the Figure 1 you would realize that the training data we are giving to a ML program needs to be specifically crafted (and that's where a lot of effort goes in any ML project) so that all important distinguishing features are identified and we have data for the same. Please note the Email column (in green) in Figure 1, is not fed to the ML algorithm and I have kept it there just for illustration.
Next step is to feed in this (Training) data (Feature set and Results) to the ML algorithm and based on this data the ML algorithm will create a model (pattern or mathematical model) which it will later use to decide whether a string is a valid email address or not.
So essentially in ML the (training) dataset we give to the program has
1. All critical features identified
2. Lots of data with as many as possible options for all the feature sets
3. Clearly state which features lead to correct results and which ones not.
But what happens if the rules to identify email changes?
So far so good, but what happens if the rules to define correct email gets modified. Let's say now we allow '~' to be a valid character so that a valid email can also have '~' character anywhere in the local part of the email string.
With conventional programming we will have to go back and simply modify the regular expression to allow for ~ to be part of email. So, we will be modifying the actual program we have written.
However, with ML all we will have to do is modify the training data to update the data corresponding to feature set we identified (in our specific example data corresponding to last row will need to be updated) and re-train the ML algo to get the new model. Then that model can be used to determine if the string is a valid email or not.
So in essence:
- ML is a completely different way of looking at a problem.
- We can definitely solve the same problems with conventional programming, however, ML is applied to problems that do not have clearly defined (fluid) rules. Hence solving that with conventional programing will be more expensive.
- ML programs learn and make decisions based on data, as the data changes the decisions changes. And since humans also learn the same way, by observing what is right and what is wrong around us, hence we term the programs as AI or ML
- The places where we have discreet set of direct rules governing the logic, those problems are best solved using conventional programming (so was our example of email identification in this Article), however, ML is best used in cases when you do not have discreet set of rules, for example lets say you have imported contacts from various social network and you know there are duplicates in contact list (since same contacts may have come from linked-in / twitter / Facebook) so to remove / merge duplicates you should go the ML route instead of conventional programming since you may find duplicate by email address / images matches / other details matches but it is not essential that any or all of the parameters will definitely match.
- In an attempt to explain the concepts of ML to programmers, I have oversimplified the Machine learning concepts and made some very basic assumptions (which I have tried to document as well)
Originally published at
https://www.linkedin.com/pulse/introduction-machine-learning-conventional-programmer-srivastava
 Business:
Business:  Call us on:
Call us on: H 92, Ground Floor. Sector 63, Noida, U.P
H 92, Ground Floor. Sector 63, Noida, U.P